
statistics — Функции математической статистики¶
Added in version 3.4.
Источник: Lib/statistics.py
Этот модуль предоставляет функции для вычисления математической статистики числовых (Real-значений) данных.
Модуль не является конкурентом сторонним библиотекам NumPy, SciPy или собственным полнофункциональным статистическим пакетам, ориентированным на профессиональных статистиков, таким как Minitab, SAS и Matlab. Она ориентирована на уровень графических и научных калькуляторов.
Если не указано явно, эти функции поддерживают int, float, Decimal и Fraction. Поведение с другими типами (как в числовой башне, так и без нее) в настоящее время не поддерживается. Коллекции со смешанными типами также не определены и зависят от реализации. Если ваши входные данные состоят из смешанных типов, вы можете использовать map(), чтобы обеспечить последовательный результат, например: map(float, input_data).
В некоторых наборах данных для представления отсутствующих данных используются значения NaN (не число). Поскольку NaN имеют необычную семантику сравнения, они вызывают неожиданное или неопределенное поведение в функциях статистики, которые сортируют данные или подсчитывают вхождения. Это касается функций median(), median_low(), median_high(), median_grouped(), mode(), multimode() и quantiles(). Значения NaN должны быть удалены перед вызовом этих функций:
>>> from statistics import median
>>> from math import isnan
>>> from itertools import filterfalse
>>> data = [20.7, float('NaN'),19.2, 18.3, float('NaN'), 14.4]
>>> sorted(data) # This has surprising behavior
[20.7, nan, 14.4, 18.3, 19.2, nan]
>>> median(data) # This result is unexpected
16.35
>>> sum(map(isnan, data)) # Number of missing values
2
>>> clean = list(filterfalse(isnan, data)) # Strip NaN values
>>> clean
[20.7, 19.2, 18.3, 14.4]
>>> sorted(clean) # Sorting now works as expected
[14.4, 18.3, 19.2, 20.7]
>>> median(clean) # This result is now well defined
18.75
Средние значения и показатели центрального расположения¶
Эти функции вычисляют среднее или типичное значение по совокупности или выборке.
Среднее арифметическое («среднее») данных. |
|
Быстрое среднее арифметическое с плавающей запятой, с дополнительным взвешиванием. |
|
Среднее геометрическое значение данных. |
|
Среднее гармоническое значение данных. |
|
Оцените плотность распределения вероятностей данных. |
|
Случайная выборка из PDF-файла, сгенерированного функцией kde(). |
|
Медиана (среднее значение) данных. |
|
Низкая медиана данных. |
|
Высокая медиана данных. |
|
Медиана (50-й процентиль) сгруппированных данных. |
|
Одиночный режим (наиболее часто встречающееся значение) дискретных или номинальных данных. |
|
Список режимов (наиболее часто встречающихся значений) дискретных или номинальных данных. |
|
Разделите данные на интервалы с равной вероятностью. |
Показатели распространения¶
Эти функции позволяют определить, насколько сильно популяция или выборка отклоняется от типичных или средних значений.
Популяционное стандартное отклонение данных. |
|
Популяционная дисперсия данных. |
|
Выборочное стандартное отклонение данных. |
|
Выборочная дисперсия данных. |
Статистика отношений между двумя входами¶
Эти функции вычисляют статистику отношений между двумя входами.
Выборочная ковариация для двух переменных. |
|
Коэффициенты корреляции Пирсона и Спирмена. |
|
Наклон и перехват для простой линейной регрессии. |
Детали функции¶
Примечание: Функции не требуют, чтобы передаваемые им данные были отсортированы. Однако для удобства чтения в большинстве примеров показаны отсортированные последовательности.
- statistics.mean(data)¶
Возвращает выборочное среднее арифметическое из данных, которые могут быть последовательностью или итерабельной переменной.
Среднее арифметическое - это сумма данных, деленная на количество точек данных. Его обычно называют «средним», хотя это лишь одно из многих различных математических средних. Это показатель центрального положения данных.
Если data пуста, будет вызвано сообщение
StatisticsError.Некоторые примеры использования:
>>> mean([1, 2, 3, 4, 4]) 2.8 >>> mean([-1.0, 2.5, 3.25, 5.75]) 2.625 >>> from fractions import Fraction as F >>> mean([F(3, 7), F(1, 21), F(5, 3), F(1, 3)]) Fraction(13, 21) >>> from decimal import Decimal as D >>> mean([D("0.5"), D("0.75"), D("0.625"), D("0.375")]) Decimal('0.5625')
Примечание
Среднее значение сильно зависит от outliers и не обязательно является типичным примером точек данных. Более надежную, хотя и менее эффективную, меру central tendency см. в
median().Выборочное среднее дает несмещенную оценку истинного среднего значения популяции, так что при среднем значении по всем возможным выборкам
mean(sample)сходится к истинному среднему значению всей популяции. Если данные представляют собой всю популяцию, а не выборку, тоmean(data)эквивалентно вычислению истинного среднего значения популяции μ.
- statistics.fmean(data, weights=None)¶
Преобразуйте данные в плавающие значения и вычислите среднее арифметическое.
Она работает быстрее, чем функция
mean(), и всегда возвращаетfloat. В качестве данных может выступать последовательность или итерируемая переменная. Если входной набор данных пуст, возвращается сообщениеStatisticsError.>>> fmean([3.5, 4.0, 5.25]) 4.25
Поддерживаются дополнительные весовые коэффициенты. Например, профессор выставляет оценку за курс, взвешивая контрольные работы на 20 %, домашние задания на 20 %, промежуточный экзамен на 30 % и итоговый экзамен на 30 %:
>>> grades = [85, 92, 83, 91] >>> weights = [0.20, 0.20, 0.30, 0.30] >>> fmean(grades, weights) 87.6
Если указаны весы, то они должны быть той же длины, что и данные, иначе будет выдано сообщение
ValueError.Added in version 3.8.
Изменено в версии 3.11: Добавлена поддержка весов.
- statistics.geometric_mean(data)¶
Преобразуйте данные в плавающие значения и вычислите среднее геометрическое.
Среднее геометрическое указывает на центральную тенденцию или типичное значение данных, используя произведение значений (в отличие от среднего арифметического, которое использует их сумму).
Вызывает ошибку
StatisticsError, если входной набор данных пуст, содержит ноль или отрицательное значение. Данные* могут быть последовательностью или итерируемой переменной.Никаких специальных усилий для достижения точных результатов не предпринимается. (Однако в будущем это может измениться).
>>> round(geometric_mean([54, 24, 36]), 1) 36.0
Added in version 3.8.
- statistics.harmonic_mean(data, weights=None)¶
Возвращает среднее гармоническое значение data, последовательность или итерабельность вещественных чисел. Если значение weights опущено или
None, то предполагается равное взвешивание.Среднее гармоническое - это обратное арифметическое
mean()взаимно обратных значений данных. Например, среднее гармоническое трех значений a, b и c будет равно3/(1/a + 1/b + 1/c). Если одно из значений равно нулю, результат будет равен нулю.Среднее гармоническое - это тип среднего, мера центрального положения данных. Его часто используют при усреднении коэффициентов или показателей, например, скорости.
Предположим, автомобиль проезжает 10 км со скоростью 40 км/ч, затем еще 10 км со скоростью 60 км/ч. Какова средняя скорость?
>>> harmonic_mean([40, 60]) 48.0
Предположим, что автомобиль едет со скоростью 40 км/ч на протяжении 5 км, а когда движение рассасывается, разгоняется до 60 км/ч на протяжении оставшихся 30 км пути. Какова средняя скорость?
>>> harmonic_mean([40, 60], weights=[5, 30]) 56.0
StatisticsErrorподнимается, если данные пусты, любой элемент меньше нуля или если взвешенная сумма не положительна.Текущий алгоритм имеет ранний выход, когда на входе встречается ноль. Это означает, что последующие входы не проверяются на достоверность. (Это поведение может измениться в будущем).
Added in version 3.6.
Изменено в версии 3.10: Добавлена поддержка весов.
- statistics.kde(data, h, kernel='normal', *, cumulative=False)¶
Kernel Density Estimation (KDE): Создание непрерывной функции плотности вероятности или кумулятивной функции распределения из дискретных выборок.
Основная идея заключается в сглаживании данных с помощью a kernel function, что помогает делать выводы о популяции на основе выборки.
Степень сглаживания регулируется параметром масштабирования h, который называется полосой пропускания. Меньшие значения подчеркивают локальные особенности, в то время как большие значения дают более гладкие результаты.
Ядро* определяет относительные веса точек данных выборки. Как правило, выбор формы ядра не имеет такого значения, как более влиятельный параметр сглаживания полосы пропускания.
Ядра, придающие некоторый вес каждой точке выборки, включают нормальное (гаусс), логистическое и сигмоидное.
Ядра, придающие вес только точкам выборки в пределах полосы пропускания, включают прямоугольные (неравномерные), треугольные, параболические (епанечников), квартальные (бивес), тривес и косинус.
Если cumulative равно true, то будет возвращена кумулятивная функция распределения.
Если последовательность data пуста, будет вызвана ошибка
StatisticsError.Wikipedia has an example, где мы можем использовать
kde(), чтобы сгенерировать и построить график функции плотности вероятности, оцененной по небольшой выборке:>>> sample = [-2.1, -1.3, -0.4, 1.9, 5.1, 6.2] >>> f_hat = kde(sample, h=1.5) >>> xarr = [i/100 for i in range(-750, 1100)] >>> yarr = [f_hat(x) for x in xarr]
Точки
xarrиyarrможно использовать для построения графика PDF: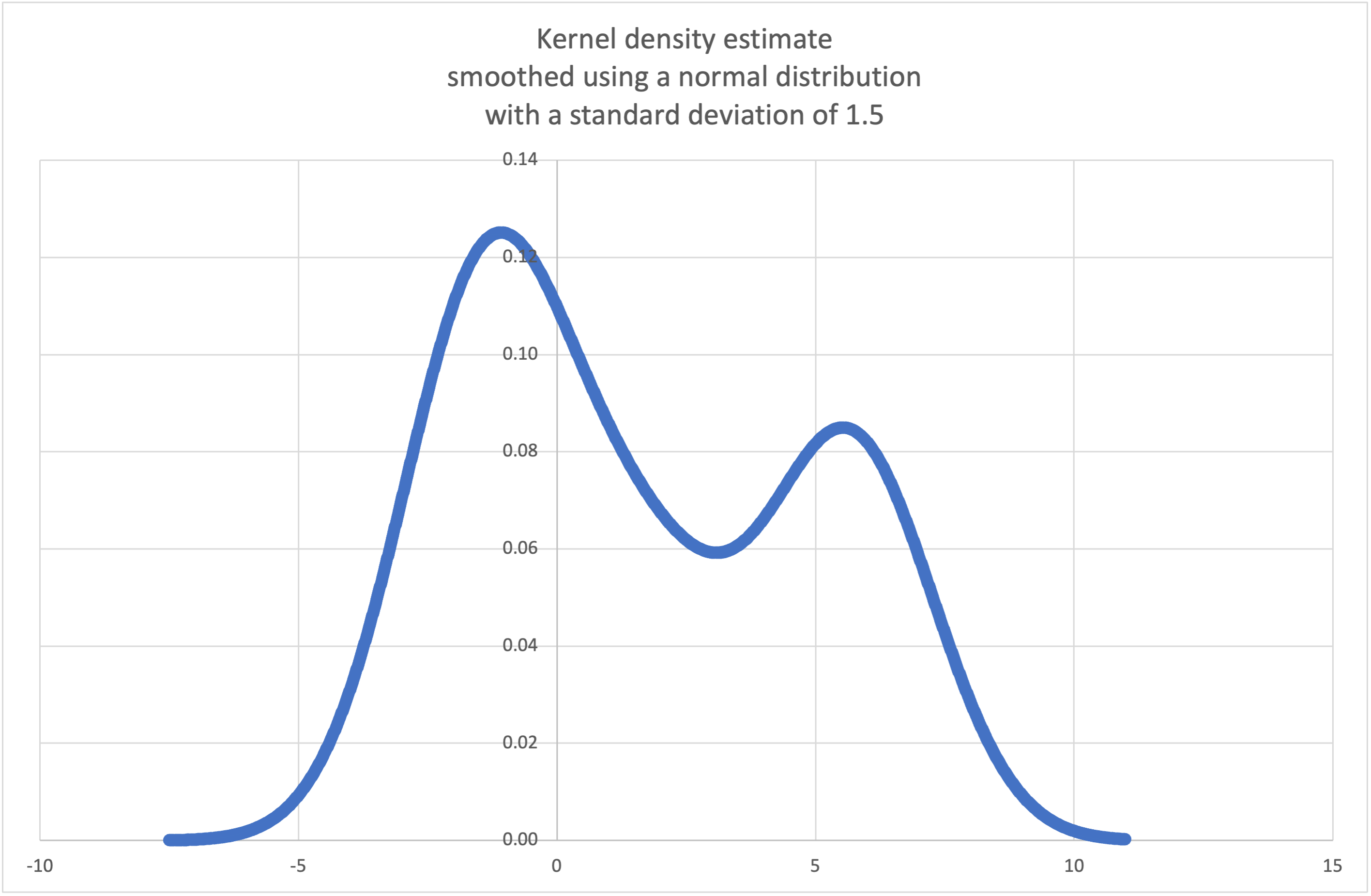
Added in version 3.13.
- statistics.kde_random(data, h, kernel='normal', *, seed=None)¶
Возвращает функцию, которая делает случайный выбор из оценочной функции плотности вероятности, полученной с помощью
kde(data, h, kernel).Предоставление семян позволяет воспроизводить выборки. В будущем значения могут немного измениться по мере внедрения более точных оценок обратного CDF ядра. В качестве семени может выступать целое число, float, str или байт.
Если последовательность data пуста, будет вызвана ошибка
StatisticsError.Продолжая пример с
kde(), мы можем использоватьkde_random()для генерации новых случайных выборок из оценочной функции плотности вероятности:>>> data = [-2.1, -1.3, -0.4, 1.9, 5.1, 6.2] >>> rand = kde_random(data, h=1.5, seed=8675309) >>> new_selections = [rand() for i in range(10)] >>> [round(x, 1) for x in new_selections] [0.7, 6.2, 1.2, 6.9, 7.0, 1.8, 2.5, -0.5, -1.8, 5.6]
Added in version 3.13.
- statistics.median(data)¶
Возвращает медиану (среднее значение) числовых данных, используя обычный метод «среднее из двух средних». Если data пуста, возвращается значение
StatisticsError. data может быть последовательностью или итерируемой переменной.Медиана является надежным показателем центрального положения, и на нее меньше влияет наличие провалов. Если количество точек данных нечетное, возвращается средняя точка данных:
>>> median([1, 3, 5]) 3
Если количество точек данных четное, медиана интерполируется путем взятия среднего из двух средних значений:
>>> median([1, 3, 5, 7]) 4.0
Этот способ подходит для тех случаев, когда данные дискретны, и вас не беспокоит, что медиана может не быть реальной точкой данных.
Если данные являются порядковыми (поддерживают операции упорядочивания), но не числовыми (не поддерживают сложение), используйте вместо них
median_low()илиmedian_high().
- statistics.median_low(data)¶
Возвращает низшую медиану числовых данных. Если data пуста, возвращается значение
StatisticsError. data может быть последовательностью или итерируемой переменной.Низшая медиана всегда входит в набор данных. Если количество точек данных нечетное, возвращается среднее значение. При четном количестве возвращается меньшее из двух средних значений.
>>> median_low([1, 3, 5]) 3 >>> median_low([1, 3, 5, 7]) 3
Используйте низкую медиану, если ваши данные дискретны и вы предпочитаете, чтобы медиана была реальной точкой данных, а не интерполированной.
- statistics.median_high(data)¶
Возвращает высокую медиану данных. Если data пуста, возвращается значение
StatisticsError. data может быть последовательностью или итерируемой переменной.Высокая медиана всегда входит в набор данных. Если количество точек данных нечетное, возвращается среднее значение. При четном количестве возвращается большее из двух средних значений.
>>> median_high([1, 3, 5]) 3 >>> median_high([1, 3, 5, 7]) 5
Используйте высокую медиану, если ваши данные дискретны и вы предпочитаете, чтобы медиана была реальной точкой данных, а не интерполированной.
- statistics.median_grouped(data, interval=1.0)¶
Оценивает медиану для числовых данных, которые были grouped or binned вокруг средних точек последовательных интервалов фиксированной ширины.
В качестве данных может выступать любой итерабельный набор числовых данных, каждое значение которого является точной серединой бина. Должно присутствовать хотя бы одно значение.
Интервал - это ширина каждого бина.
Например, демографическая информация может быть обобщена на последовательные десятилетние возрастные группы, каждая из которых представлена 5-летними средними точками интервалов:
>>> from collections import Counter >>> demographics = Counter({ ... 25: 172, # 20 to 30 years old ... 35: 484, # 30 to 40 years old ... 45: 387, # 40 to 50 years old ... 55: 22, # 50 to 60 years old ... 65: 6, # 60 to 70 years old ... }) ...
50-й процентиль (медиана) - это 536-й человек из 1071 члена когорты. Этот человек относится к возрастной группе от 30 до 40 лет.
Обычная функция
median()предполагает, что каждому представителю возрастной группы триценариев ровно 35 лет. Более правдоподобным является предположение, что 484 члена этой возрастной группы равномерно распределены между 30 и 40 годами. Для этого мы используем функциюmedian_grouped():>>> data = list(demographics.elements()) >>> median(data) 35 >>> round(median_grouped(data, interval=10), 1) 37.5
Вызывающая сторона отвечает за то, чтобы точки данных были разделены точным кратным интервалом. Это необходимо для получения корректного результата. Функция не проверяет это предварительное условие.
Входными данными могут быть любые числовые типы, которые могут быть преобразованы в float на этапе интерполяции.
- statistics.mode(data)¶
Возвращает единственную наиболее распространенную точку данных из дискретных или номинальных данных. Режим (если он существует) является наиболее типичным значением и служит мерой центрального положения.
Если существует несколько режимов с одинаковой частотой, возвращается первый из них, встретившийся в данных. Если вместо этого требуется наименьший или наибольший из них, используйте
min(multimode(data))илиmax(multimode(data)). Если входные данные пусты, возвращается значениеStatisticsError.modeпредполагает дискретные данные и возвращает единственное значение. Это стандартная трактовка режима, которую обычно преподают в школах:>>> mode([1, 1, 2, 3, 3, 3, 3, 4]) 3
Режим уникален тем, что это единственная статистика в этом пакете, которая также применима к номинальным (нечисловым) данным:
>>> mode(["red", "blue", "blue", "red", "green", "red", "red"]) 'red'
Изменено в версии 3.8: Теперь обрабатывает мультимодальные наборы данных, возвращая первый найденный режим. Раньше при обнаружении более одного режима возвращалось значение
StatisticsError.
- statistics.multimode(data)¶
Возвращает список наиболее часто встречающихся значений в порядке их первого появления в data. Возвращает несколько результатов, если режимов несколько, или пустой список, если data пуста:
>>> multimode('aabbbbccddddeeffffgg') ['b', 'd', 'f'] >>> multimode('') []
Added in version 3.8.
- statistics.pstdev(data, mu=None)¶
Возвращает стандартное отклонение популяции (квадратный корень из дисперсии популяции). Аргументы и другие подробности см. в разделе
pvariance().>>> pstdev([1.5, 2.5, 2.5, 2.75, 3.25, 4.75]) 0.986893273527251
- statistics.pvariance(data, mu=None)¶
Возвращает дисперсию популяции data, непустую последовательность или итерабельность вещественных чисел. Дисперсия, или второй момент относительно среднего, - это мера изменчивости (разброса или дисперсии) данных. Большая дисперсия указывает на то, что данные разбросаны; малая дисперсия указывает на то, что они тесно сгруппированы вокруг среднего значения.
Если указан необязательный второй аргумент mu, то это должно быть среднее популяционное значение данных. Он также может использоваться для вычисления второго момента в окрестности точки, которая не является средним значением. Если он отсутствует или
None(по умолчанию), автоматически вычисляется среднее арифметическое.Используйте эту функцию для расчета дисперсии всей совокупности. Для оценки дисперсии по выборке обычно лучше использовать функцию
variance().Вызывает
StatisticsError, если данные пусты.Примеры:
>>> data = [0.0, 0.25, 0.25, 1.25, 1.5, 1.75, 2.75, 3.25] >>> pvariance(data) 1.25
Если вы уже вычислили среднее значение ваших данных, вы можете передать его в качестве необязательного второго аргумента mu, чтобы избежать повторного вычисления:
>>> mu = mean(data) >>> pvariance(data, mu) 1.25
Поддерживаются десятичные и дробные числа:
>>> from decimal import Decimal as D >>> pvariance([D("27.5"), D("30.25"), D("30.25"), D("34.5"), D("41.75")]) Decimal('24.815') >>> from fractions import Fraction as F >>> pvariance([F(1, 4), F(5, 4), F(1, 2)]) Fraction(13, 72)
Примечание
При обращении ко всей популяции это дает дисперсию популяции σ². При обращении к выборке вместо этого получается смещенная выборочная дисперсия s², также известная как дисперсия с N степенями свободы.
Если вам каким-то образом известно истинное среднее значение популяции μ, вы можете использовать эту функцию для расчета дисперсии выборки, указав в качестве второго аргумента известное среднее значение популяции. При условии, что точки данных являются случайной выборкой из популяции, результат будет несмещенной оценкой дисперсии популяции.
- statistics.stdev(data, xbar=None)¶
Возвращает стандартное отклонение выборки (квадратный корень из дисперсии выборки). Аргументы и другие подробности см. в разделе
variance().>>> stdev([1.5, 2.5, 2.5, 2.75, 3.25, 4.75]) 1.0810874155219827
- statistics.variance(data, xbar=None)¶
Возвращает выборочную дисперсию data, итерабельную переменную, состоящую как минимум из двух вещественных чисел. Дисперсия, или второй момент относительно среднего, - это мера изменчивости (разброса или дисперсии) данных. Большая дисперсия указывает на то, что данные разбросаны; малая дисперсия указывает на то, что они тесно сгруппированы вокруг среднего значения.
Если указан необязательный второй аргумент xbar, то это должно быть выборочное среднее значение данных. Если он отсутствует или равен
None(по умолчанию), среднее значение вычисляется автоматически.Используйте эту функцию, когда ваши данные представляют собой выборку из популяции. Чтобы вычислить дисперсию всей совокупности, смотрите
pvariance().Вызывает
StatisticsError, если данные имеют меньше двух значений.Примеры:
>>> data = [2.75, 1.75, 1.25, 0.25, 0.5, 1.25, 3.5] >>> variance(data) 1.3720238095238095
Если вы уже вычислили выборочное среднее значение ваших данных, вы можете передать его в качестве необязательного второго аргумента xbar, чтобы избежать повторного вычисления:
>>> m = mean(data) >>> variance(data, m) 1.3720238095238095
Эта функция не пытается проверить, что вы передали фактическое среднее значение в качестве xbar. Использование произвольных значений для xbar может привести к недостоверным или невозможным результатам.
Поддерживаются десятичные и дробные значения:
>>> from decimal import Decimal as D >>> variance([D("27.5"), D("30.25"), D("30.25"), D("34.5"), D("41.75")]) Decimal('31.01875') >>> from fractions import Fraction as F >>> variance([F(1, 6), F(1, 2), F(5, 3)]) Fraction(67, 108)
Примечание
Это выборочная дисперсия s² с поправкой Бесселя, также известная как дисперсия с N-1 степенями свободы. При условии, что точки данных являются репрезентативными (например, независимыми и одинаково распределенными), результат должен быть несмещенной оценкой истинной дисперсии популяции.
Если вы каким-то образом знаете фактическое среднее значение популяции μ, вам следует передать его в функцию
pvariance()в качестве параметра mu, чтобы получить дисперсию выборки.
- statistics.quantiles(data, *, n=4, method='exclusive')¶
Разделите данные на n непрерывных интервалов с равной вероятностью. Возвращает список точек
n - 1, разделяющих интервалы.Установите n на 4 для квартилей (по умолчанию). Установите n на 10 для децилей. Задайте n равным 100 для перцентилей, что дает 99 точек среза, которые разделяют данные на 100 групп равного размера. Вызывает
StatisticsError, если n не меньше 1.В качестве data может выступать любая итерируемая переменная, содержащая данные выборки. Для получения значимых результатов количество точек данных в data должно быть больше, чем n. Вызывает
StatisticsError, если нет хотя бы одной точки данных.Точки среза линейно интерполируются от двух ближайших точек данных. Например, если точка среза находится на одной трети расстояния между двумя значениями выборки,
100и112, то точка среза будет оцениваться как104.Метод вычисления квантилей может быть различным в зависимости от того, включают ли данные или исключают из совокупности самые низкие и самые высокие возможные значения.
Метод по умолчанию - «эксклюзивный» - используется для данных, отобранных из популяции, которая может иметь более экстремальные значения, чем те, которые встречаются в выборках. Часть популяции, попадающая ниже i-го из m отсортированных точек данных, вычисляется как
i / (m + 1). Учитывая девять значений выборки, метод сортирует их и присваивает следующие процентили: 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%.Установка метода в значение «inclusive» используется для описания данных о популяции или для выборок, которые, как известно, включают самые экстремальные значения из популяции. Минимальное значение в data рассматривается как 0-й процентиль, а максимальное значение - как 100-й процентиль. Часть популяции, попадающая ниже i-го из m отсортированных точек данных, вычисляется как
(i - 1) / (m - 1). Если дано 11 значений выборки, метод сортирует их и присваивает следующие процентили: 0%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%.# Decile cut points for empirically sampled data >>> data = [105, 129, 87, 86, 111, 111, 89, 81, 108, 92, 110, ... 100, 75, 105, 103, 109, 76, 119, 99, 91, 103, 129, ... 106, 101, 84, 111, 74, 87, 86, 103, 103, 106, 86, ... 111, 75, 87, 102, 121, 111, 88, 89, 101, 106, 95, ... 103, 107, 101, 81, 109, 104] >>> [round(q, 1) for q in quantiles(data, n=10)] [81.0, 86.2, 89.0, 99.4, 102.5, 103.6, 106.0, 109.8, 111.0]
Added in version 3.8.
Изменено в версии 3.13: Больше не возникает исключение для входа с единственной точкой данных. Это позволяет строить квантильные оценки по одной точке выборки за раз, постепенно уточняя их с каждой новой точкой данных.
- statistics.covariance(x, y, /)¶
Возвращает выборочную ковариацию двух входов x и y. Ковариация - это мера совместной изменчивости двух входов.
Оба входа должны иметь одинаковую длину (не менее двух), в противном случае выводится
StatisticsError.Примеры:
>>> x = [1, 2, 3, 4, 5, 6, 7, 8, 9] >>> y = [1, 2, 3, 1, 2, 3, 1, 2, 3] >>> covariance(x, y) 0.75 >>> z = [9, 8, 7, 6, 5, 4, 3, 2, 1] >>> covariance(x, z) -7.5 >>> covariance(z, x) -7.5
Added in version 3.10.
- statistics.correlation(x, y, /, *, method='linear')¶
Возвращает значение Pearson’s correlation coefficient для двух входных данных. Коэффициент корреляции Пирсона r принимает значения от -1 до +1. Он измеряет силу и направление линейной связи.
Если метод имеет значение «ranked», вычисляется Spearman’s rank correlation coefficient для двух входных данных. Данные заменяются рангами. Значения рангов усредняются, чтобы равные значения получили одинаковые ранги. Полученный коэффициент измеряет силу монотонной зависимости.
Коэффициент корреляции Спирмена подходит для порядковых данных или для непрерывных данных, которые не удовлетворяют требованиям линейной пропорции для коэффициента корреляции Пирсона.
Оба входа должны иметь одинаковую длину (не менее двух) и не должны быть постоянными, иначе будет выведен
StatisticsError.Пример с Kepler’s laws of planetary motion:
>>> # Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, and Neptune >>> orbital_period = [88, 225, 365, 687, 4331, 10_756, 30_687, 60_190] # days >>> dist_from_sun = [58, 108, 150, 228, 778, 1_400, 2_900, 4_500] # million km >>> # Show that a perfect monotonic relationship exists >>> correlation(orbital_period, dist_from_sun, method='ranked') 1.0 >>> # Observe that a linear relationship is imperfect >>> round(correlation(orbital_period, dist_from_sun), 4) 0.9882 >>> # Demonstrate Kepler's third law: There is a linear correlation >>> # between the square of the orbital period and the cube of the >>> # distance from the sun. >>> period_squared = [p * p for p in orbital_period] >>> dist_cubed = [d * d * d for d in dist_from_sun] >>> round(correlation(period_squared, dist_cubed), 4) 1.0
Added in version 3.10.
Изменено в версии 3.12: Добавлена поддержка коэффициента ранговой корреляции Спирмена.
- statistics.linear_regression(x, y, /, *, proportional=False)¶
Возвращает наклон и перехват параметров simple linear regression, оцененных с помощью обыкновенных наименьших квадратов. Простая линейная регрессия описывает связь между независимой переменной x и зависимой переменной y в терминах этой линейной функции:
y = наклон * x + перехват + шум.
где
slopeиintercept- параметры регрессии, которые оцениваются, аnoise- изменчивость данных, которая не объясняется линейной регрессией (она равна разнице между предсказанными и фактическими значениями зависимой переменной).Оба входа должны быть одинаковой длины (не менее двух), а независимая переменная x не может быть постоянной; в противном случае выдается сообщение
StatisticsError.Например, мы можем использовать release dates of the Monty Python films, чтобы предсказать суммарное количество фильмов Monty Python, которое было бы создано к 2019 году, если бы они сохранили прежний темп.
>>> year = [1971, 1975, 1979, 1982, 1983] >>> films_total = [1, 2, 3, 4, 5] >>> slope, intercept = linear_regression(year, films_total) >>> round(slope * 2019 + intercept) 16
Если верно значение proportional, предполагается, что независимая переменная x и зависимая переменная y прямо пропорциональны. Данные подгоняются к прямой, проходящей через начало координат. Поскольку пересечение всегда будет равно 0,0, линейная функция упрощается до:
y = наклон * x + шум.
Продолжая пример с
correlation(), посмотрим, насколько хорошо модель, основанная на крупных планетах, может предсказать орбитальные расстояния для карликовых планет:>>> model = linear_regression(period_squared, dist_cubed, proportional=True) >>> slope = model.slope >>> # Dwarf planets: Pluto, Eris, Makemake, Haumea, Ceres >>> orbital_periods = [90_560, 204_199, 111_845, 103_410, 1_680] # days >>> predicted_dist = [math.cbrt(slope * (p * p)) for p in orbital_periods] >>> list(map(round, predicted_dist)) [5912, 10166, 6806, 6459, 414] >>> [5_906, 10_152, 6_796, 6_450, 414] # actual distance in million km [5906, 10152, 6796, 6450, 414]
Added in version 3.10.
Изменено в версии 3.11: Добавлена поддержка пропорционального.
Исключения¶
Определено одно исключение:
- exception statistics.StatisticsError¶
Подкласс
ValueErrorдля исключений, связанных со статистикой.
NormalDist объектов¶
NormalDist - это инструмент для создания и манипулирования нормальными распределениями random variable. Это класс, который рассматривает среднее и стандартное отклонение измерений данных как единое целое.
Нормальные распределения возникают из Central Limit Theorem и находят широкое применение в статистике.
- class statistics.NormalDist(mu=0.0, sigma=1.0)¶
Возвращает новый объект NormalDist, где mu представляет arithmetic mean, а sigma - standard deviation.
Если сигма отрицательна, повышается
StatisticsError.- mean¶
Свойство для arithmetic mean нормального распределения, доступное только для чтения.
- stdev¶
Свойство для standard deviation нормального распределения, доступное только для чтения.
- variance¶
Свойство только для чтения для variance нормального распределения. Равна квадрату стандартного отклонения.
- classmethod from_samples(data)¶
Создает экземпляр нормального распределения с параметрами mu и sigma, оцененными из данных с помощью
fmean()иstdev().Данные data могут быть любыми iterable и должны состоять из значений, которые можно преобразовать к типу
float. Если data не содержит по крайней мере двух элементов, то выполняется преобразование к типуStatisticsError, поскольку для оценки центрального значения требуется по крайней мере одна точка, а для оценки дисперсии - по крайней мере две точки.
- samples(n, *, seed=None)¶
Генерирует n случайных выборок для заданных среднего и стандартного отклонения. Возвращает
listизfloatзначений.Если задано значение seed, создается новый экземпляр генератора случайных чисел. Это полезно для создания воспроизводимых результатов даже в многопоточном контексте.
Изменено в версии 3.13.
Перешли на более быстрый алгоритм. Чтобы воспроизвести примеры из предыдущих версий, используйте
random.seed()иrandom.gauss().
- pdf(x)¶
Используя probability density function (pdf), вычислите относительную вероятность того, что случайная величина X окажется вблизи заданного значения x. Математически это предел отношения
P(x <= X < x+dx) / dxпо мере приближения dx к нулю.Относительная вероятность вычисляется как вероятность того, что образец попадет в узкий диапазон, деленная на ширину этого диапазона (отсюда слово «плотность»). Поскольку вероятность определяется относительно других точек, ее значение может быть больше
1.0.
- cdf(x)¶
Используя cumulative distribution function (cdf), вычислите вероятность того, что случайная величина X будет меньше или равна x. Математически это записывается
P(X <= x).
- inv_cdf(p)¶
Вычислите обратную кумулятивную функцию распределения, также известную как функция quantile function или percent-point. Математически она записывается
x : P(X <= x) = p.Находит значение x случайной переменной X, при котором вероятность того, что переменная будет меньше или равна этому значению, равна заданной вероятности p.
- overlap(other)¶
Измеряет согласие между двумя нормальными распределениями вероятностей. Возвращает значение от 0,0 до 1,0, давая the overlapping area for the two probability density functions.
- quantiles(n=4)¶
Разбивает нормальное распределение на n непрерывных интервалов с равной вероятностью. Возвращает список (n - 1) точек среза, разделяющих интервалы.
Установите n на 4 для квартилей (по умолчанию). Установите n на 10 для децилей. Для перцентилей установите n равным 100, что дает 99 точек среза, которые разделяют нормальное распределение на 100 групп равного размера.
- zscore(x)¶
Вычислите Standard Score, описывающий x в терминах количества стандартных отклонений выше или ниже среднего значения нормального распределения:
(x - mean) / stdev.Added in version 3.9.
Экземпляры
NormalDistподдерживают сложение, вычитание, умножение и деление на константу. Эти операции используются для перевода и масштабирования. Например:>>> temperature_february = NormalDist(5, 2.5) # Celsius >>> temperature_february * (9/5) + 32 # Fahrenheit NormalDist(mu=41.0, sigma=4.5)
Деление константы на экземпляр
NormalDistне поддерживается, поскольку результат не будет нормально распределен.Поскольку нормальные распределения возникают в результате аддитивных эффектов независимых переменных, можно add and subtract two independent normally distributed random variables представить как экземпляры
NormalDist. Например:>>> birth_weights = NormalDist.from_samples([2.5, 3.1, 2.1, 2.4, 2.7, 3.5]) >>> drug_effects = NormalDist(0.4, 0.15) >>> combined = birth_weights + drug_effects >>> round(combined.mean, 1) 3.1 >>> round(combined.stdev, 1) 0.5
Added in version 3.8.
Примеры и рецепты¶
Классические задачи на вероятность¶
NormalDist легко решает классические вероятностные задачи.
Например, учитывая historical data for SAT exams, что баллы распределены нормально со средним значением 1060 и стандартным отклонением 195, определите процент студентов, набравших от 1100 до 1200 баллов после округления до ближайшего целого числа:
>>> sat = NormalDist(1060, 195)
>>> fraction = sat.cdf(1200 + 0.5) - sat.cdf(1100 - 0.5)
>>> round(fraction * 100.0, 1)
18.4
Найдите значения quartiles и deciles для баллов SAT:
>>> list(map(round, sat.quantiles()))
[928, 1060, 1192]
>>> list(map(round, sat.quantiles(n=10)))
[810, 896, 958, 1011, 1060, 1109, 1162, 1224, 1310]
Входы Монте-Карло для имитационного моделирования¶
Чтобы оценить распределение для модели, которую нелегко решить аналитически, NormalDist может генерировать входные образцы для Monte Carlo simulation:
>>> def model(x, y, z):
... return (3*x + 7*x*y - 5*y) / (11 * z)
...
>>> n = 100_000
>>> X = NormalDist(10, 2.5).samples(n, seed=3652260728)
>>> Y = NormalDist(15, 1.75).samples(n, seed=4582495471)
>>> Z = NormalDist(50, 1.25).samples(n, seed=6582483453)
>>> quantiles(map(model, X, Y, Z))
[1.4591308524824727, 1.8035946855390597, 2.175091447274739]
Аппроксимация биномиальных распределений¶
Нормальное распределение может быть использовано для приближения к Binomial distributions, когда размер выборки велик и вероятность успешного испытания близка к 50%.
Например, на конференции по открытому коду присутствуют 750 человек, а два зала рассчитаны на 500 человек. В одном из залов рассказывают о Python, в другом - о Ruby. На предыдущих конференциях 65 % слушателей предпочитали слушать доклады по Python. Если предположить, что предпочтения аудитории не изменились, какова вероятность того, что зал для Python останется в пределах своей вместимости?
>>> n = 750 # Sample size
>>> p = 0.65 # Preference for Python
>>> q = 1.0 - p # Preference for Ruby
>>> k = 500 # Room capacity
>>> # Approximation using the cumulative normal distribution
>>> from math import sqrt
>>> round(NormalDist(mu=n*p, sigma=sqrt(n*p*q)).cdf(k + 0.5), 4)
0.8402
>>> # Exact solution using the cumulative binomial distribution
>>> from math import comb, fsum
>>> round(fsum(comb(n, r) * p**r * q**(n-r) for r in range(k+1)), 4)
0.8402
>>> # Approximation using a simulation
>>> from random import seed, binomialvariate
>>> seed(8675309)
>>> mean(binomialvariate(n, p) <= k for i in range(10_000))
0.8406
Наивный байесовский классификатор¶
Нормальные распределения часто встречаются в задачах машинного обучения.
В Википедии есть nice example of a Naive Bayesian Classifier. Задача состоит в том, чтобы предсказать пол человека по измерениям нормально распределенных признаков, включая рост, вес и размер ноги.
Нам дан обучающий набор данных с измерениями восьми человек. Предполагается, что измерения распределены нормально, поэтому мы суммируем данные с помощью NormalDist:
>>> height_male = NormalDist.from_samples([6, 5.92, 5.58, 5.92])
>>> height_female = NormalDist.from_samples([5, 5.5, 5.42, 5.75])
>>> weight_male = NormalDist.from_samples([180, 190, 170, 165])
>>> weight_female = NormalDist.from_samples([100, 150, 130, 150])
>>> foot_size_male = NormalDist.from_samples([12, 11, 12, 10])
>>> foot_size_female = NormalDist.from_samples([6, 8, 7, 9])
Далее мы сталкиваемся с новым человеком, чьи параметры известны, но пол неизвестен:
>>> ht = 6.0 # height
>>> wt = 130 # weight
>>> fs = 8 # foot size
Начиная с 50% prior probability того, что вы являетесь мужчиной или женщиной, мы вычисляем апостериор как отношение апостериор к произведению вероятностей для измерений признаков с учетом пола:
>>> prior_male = 0.5
>>> prior_female = 0.5
>>> posterior_male = (prior_male * height_male.pdf(ht) *
... weight_male.pdf(wt) * foot_size_male.pdf(fs))
>>> posterior_female = (prior_female * height_female.pdf(ht) *
... weight_female.pdf(wt) * foot_size_female.pdf(fs))
Окончательное предсказание получает наибольший апостериор. Это известно как maximum a posteriori или MAP:
>>> 'male' if posterior_male > posterior_female else 'female'
'female'